Analyzing the Midnight Blizzard Eviction Plan
Disclaimer: My professional background is outside of cloud environments, and I am not an Azure SME. I built this lab and wrote this post as a hands-on exercise to teach myself cloud incident response and Azure identity mechanics. While there may be technical imperfections, this documents my learning journey into the complexities of OAuth and eviction strategies.
The Midnight Blizzard attack is a stark case study in how threat actors leverage compromised OAuth applications for persistent access. While analyzing the breach, I wanted to better understand the specific mechanics required to remove an adversary once they've established this level of control; so I rebuilt the attack chain in an Azure lab environment.
This post documents my approach to a strategic eviction plan for this scenario. I break down the necessary sequence of operations and show why getting that sequence wrong can leave an attacker in your environment long after you think you've kicked them out.
What I Recreated
Rather than rehash the full attack chain here, the Wiz breakdown is worth reading in full: Midnight Blizzard: Microsoft Breach Analysis and Best Practices. I followed it closely to build out my lab: malicious apps, excessive permissions, and rogue admin accounts.
The important thing to understand going into the eviction plan is that by the end of the attack chain, the threat actor has two independent paths into the production environment: the legacy test app with broad MS Graph permissions, and the malicious exfil app with full_access_as_app on Exchange. Both footholds have to be addressed, and how you address them, and in what order, is what the rest of this post is about.
The one deviation from the original attack: since I don't have mailboxes to exfil from, I swapped
full_access_as_appforUser.Read.Allon the malicious exfil app. It's a different target, but the mechanics are identical, an overprivileged app using a bearer token to pull data it shouldn't have access to.
Why Sequencing Is Everything
This is the part I wanted to practice hands-on, because it's easy to understand in theory and easy to get wrong under pressure.
The intuitive response when you discover a malicious app exfiltrating data is to go straight for it: revoke the OAuth grant, and rotate the secret. That feels decisive. The problem is that none of those actions immediately invalidate a bearer token that's already been issued.
The wrong sequence — mitigation before protection:
In my lab, I simulated an active exfiltration session using a valid bearer token obtained by the malicious exfil app. This app was registered in my legacy-test tenant with User.Read.All permissions, and the rogue backupadmin account in my prod tenant granted it consent giving it direct access to prod data. To demonstrate secret rotation, I deleted the client secret entirely so there's no ambiguity: the credential is gone, and we'll see whether that stops anything.

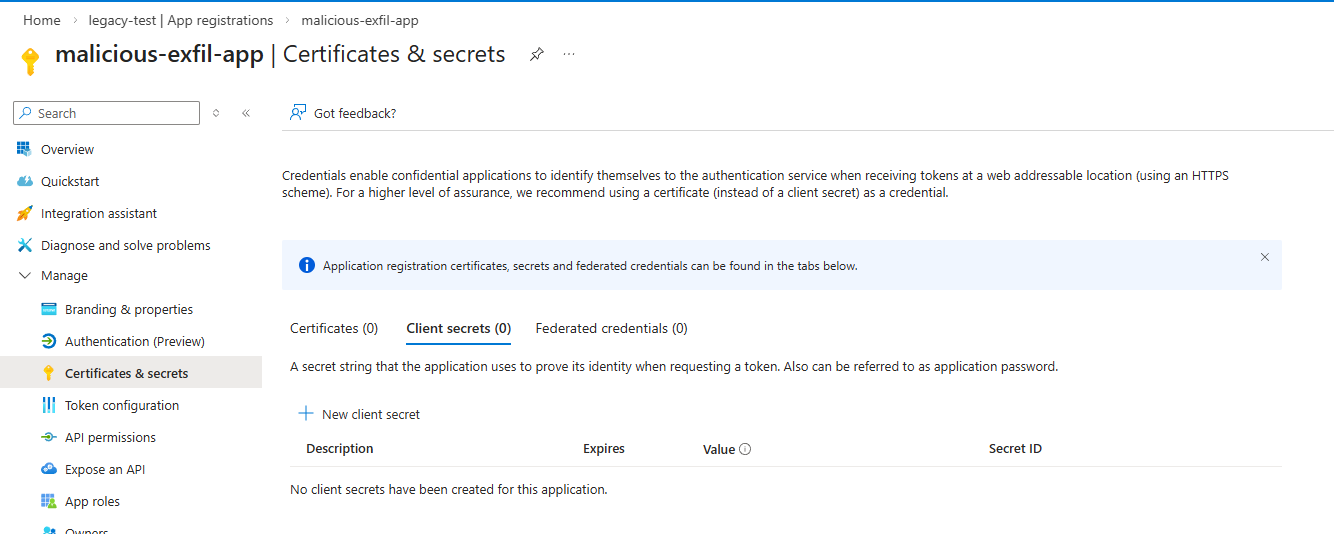
It didn't stop anything. The bearer token was still valid. The attacker can no longer request new tokens once the secret is gone, but the existing token continues to work until it naturally expires. During that entire window, exfiltration continues uninterrupted. Worse, the attacker still has access to the legacy-test tenant and could rotate the secret themselves to mint a fresh token, putting you right back to square one.
This is the gap that gets organizations into trouble. They see a mitigation action complete successfully and assume the threat is neutralized, when in reality the attacker is still live.
The right sequence — protection first:
This time I started by disabling the malicious-exfil-app Service Principal in the prod tenant before touching anything else. Almost immediately after disabling the Service Principal, my Graph API request to "exfil" data fails.
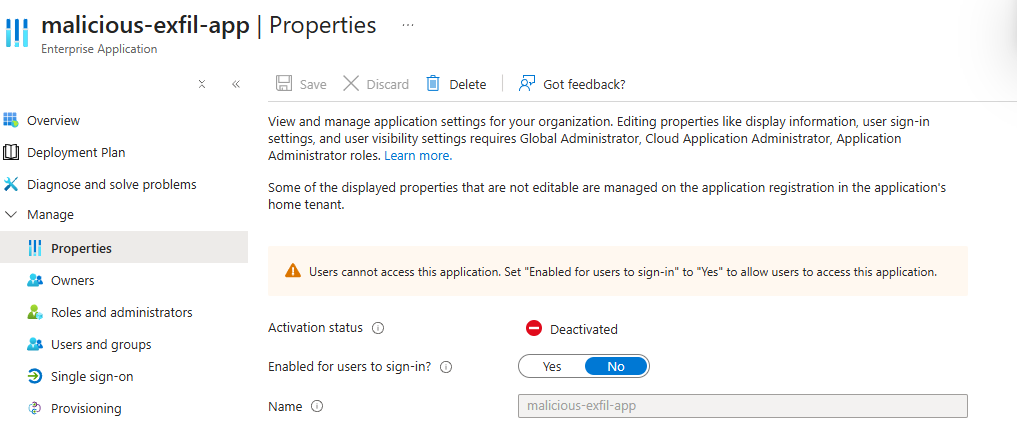

Exfiltration is stopped, but the attacker still has a persistent rogue admin in the prod tenant and access to the legacy-test tenant, which they could use to deploy another malicious app and re-consent it in prod within minutes. This is why the remaining steps need to be executed quickly and in order:
- Disable the rogue
backupadminaccount in the prod tenant. - Disable the
legacy-test-appservice principal in thelegacy-testtenant — this was the vector that enabled lateral movement from the test environment into prod in the first place. - Disable the initially compromised user account in the
legacy-testtenant.
At this point the attacker has no active access path into either environment, and whats left is cleanup. Delete the rogue backupadmin account, permanently delete the malicious apps, and for the legacy-test-app, if it can't be deleted, tighten its permissions and rotate its secrets before bringing it back into service.
What I Learned
The bigger lesson, before even thinking about eviction, was understanding how multi-tenant OAuth applications create attack surface that isn't immediately obvious. A legacy app sitting in a forgotten test tenant had pre-consented permissions reaching directly into a production environment. That trust relationship isn't visible from the prod tenant at a glance and it's exactly the kind of thing that goes unnoticed until an attacker finds it first.
I'm sure there are gaps and better approaches here and I'd genuinely welcome any corrections. But for anyone else coming from a non-cloud background who's trying to wrap their head around OAuth eviction, hopefully this saves you some of the trial and error.